2025.04.30 支持 Qwen3 系列开源模型
 极客智坊已引入对 Qwen3 系列开源模型的支持,该系列所有模型均实现了思考模式和非思考模式的有效融合,且支持在对话中切换不同模式,欢迎体验👉
极客智坊已引入对 Qwen3 系列开源模型的支持,该系列所有模型均实现了思考模式和非思考模式的有效融合,且支持在对话中切换不同模式,欢迎体验👉
- 通义千问3-235B-A22B:通义千问3 235B 参数版本(激活22B),推理能力超过 QwQ、通用能力超过 Qwen2.5-72B-Instruct
- 通义千问3-235B-A22B 免费版:Qwen3-235B-A22B 免费版本(含API调用)
- 通义千问3-30B-A3B:通义千问3 30B 参数版本(激活3B),推理能力比肩 QwQ-32B、通用能力超过 Qwen2.5-14B
- 通义千问3-30B-A3B 免费版:通义千问3-30B-A3B 免费版本(含API调用)
- 通义千问3-32B:通义千问3 30B 参数版本,推理能力超过 QwQ、通用能力超过 Qwen2.5-32B-Instruct
- 通义千问3-32B 免费版:通义千问3-32B 免费版本(含API调用)
- 通义千问3-14B:通义千问3 14B 参数版本,通用能力超过 Qwen2.5-14B
- 通义千问3-14B 免费版:通义千问3-14B 免费版本(含API调用)
- 通义千问3-8B:通义千问3 8B 参数版本,通用能力超过 Qwen2.5-7B
- 通义千问3-8B 免费版:通义千问3-8B 免费版本(含API调用)
- 通义千问3-4B:通义千问3 4B 参数版本,通用能力超过 Qwen2.5 小规模系列
- 通义千问3-4B 免费版:通义千问3-4B 免费版本(含API调用)
- 通义千问3-1.7B:通义千问3 1.7B 参数版本,通用能力超过 Qwen2.5 小规模系列
- 通义千问3-1.7B 免费版:通义千问3-1.7B 免费版本(含API调用)
- 通义千问3-0.6B:通义千问3 0.6B 参数版本,通用能力超过 Qwen2.5 小规模系列
- 通义千问3-0.6B 免费版:通义千问3-0.6B 免费版本(含API调用)
2025.04.29 支持 GLM 4 系列开源模型
 极客智坊已引入对 GLM 4 系列开源模型的支持,欢迎体验👉
极客智坊已引入对 GLM 4 系列开源模型的支持,欢迎体验👉
- GLM-4-32B:智谱清言开源多语言多模态对话模型,性能比肩 GPT-4o 和 DeepSeek-V3-0324
- GLM-4-32B 免费版:GLM-4-32B 免费版本(含API调用)
- GLM-Z1-32B:GLM-4-32B 推理增强版本,适合需要谨慎推理、多步骤推理,或进行正式推导的场景
- GLM-Z1-32B 免费版:GLM-Z1-32B 免费版本(含API调用)
 更多关于 API 调用和第三方应用接入的细节,请查阅极客智坊文档教程。
更多关于 API 调用和第三方应用接入的细节,请查阅极客智坊文档教程。
2025.04.25 支持 GPT Image 1
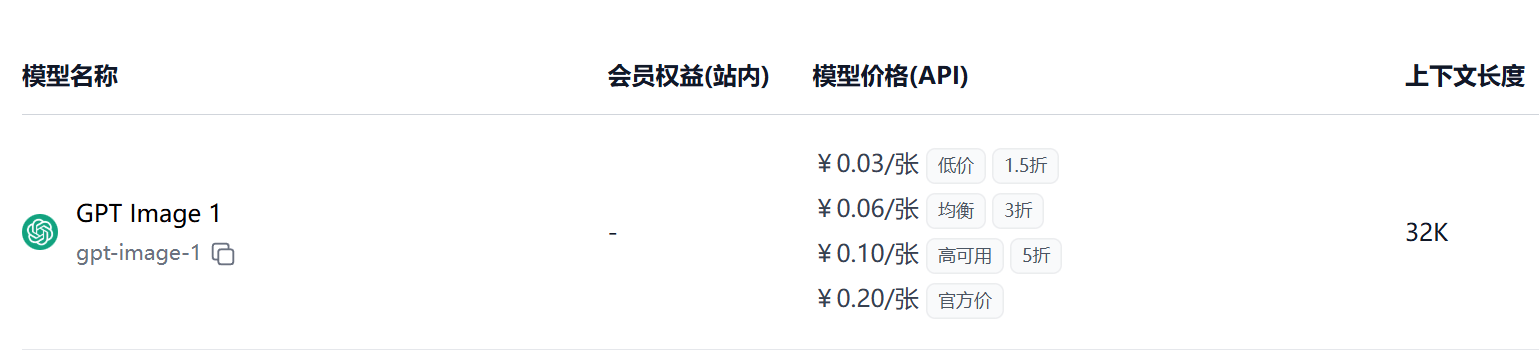
 极客智坊已引入对 OpenAI 最新发布的最先进画图模型 GPT Image 1 的支持,该模型支持文生图、图生图功能,输入文本长度扩展至 32K,欢迎体验👉
支持通过极客智坊画图 API 进行图片生成和编辑,为降低调用成本,极客智坊提供了最低 0.03 元/张的低价接口,你可以在模型广场进行查看和选用:
极客智坊已引入对 OpenAI 最新发布的最先进画图模型 GPT Image 1 的支持,该模型支持文生图、图生图功能,输入文本长度扩展至 32K,欢迎体验👉
支持通过极客智坊画图 API 进行图片生成和编辑,为降低调用成本,极客智坊提供了最低 0.03 元/张的低价接口,你可以在模型广场进行查看和选用:
2025.04.24 支持所有智谱清言搜索引擎
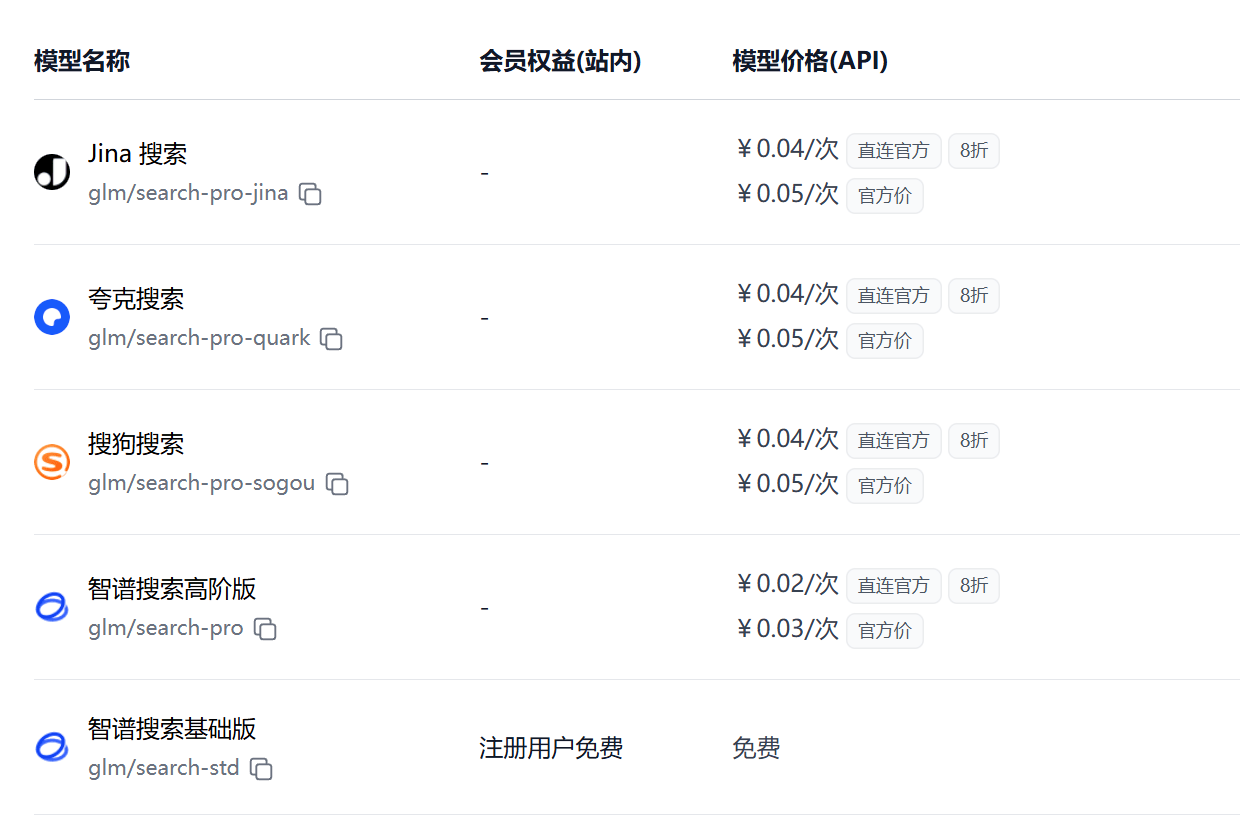
 极客智坊已引入对智谱清言所有自研/第三方搜索引擎工具的支持,欢迎体验👉
极客智坊已引入对智谱清言所有自研/第三方搜索引擎工具的支持,欢迎体验👉
- 智谱搜索基础版:智谱自研搜索基础版,速度快,高性价比,限时免费至2025年5月31日
- 智谱搜索高阶版:智谱自研搜索Pro版,搜索结果召回率更高
- 搜狗搜索:耗时短,支持搜狗百科、搜狗问问检索
- 夸克搜索:搜索时效性强、覆盖多行业领域
- Jina搜索:基于 Jina AI 底座,搜索准确性更高
 API 调用示例参考联网对话文档。
API 调用示例参考联网对话文档。
2025.04.20 支持 Gemini 2.5 Flash
 极客智坊已引入对 Gemini 2.5 Flash 预览版的支持,在 2.0 Flash 的基础上,这个新版本在推理能力上实现了重大突破,同时比 Gemini 2.5 Pro 更具性价比,响应速度更快,欢迎体验:
极客智坊已引入对 Gemini 2.5 Flash 预览版的支持,在 2.0 Flash 的基础上,这个新版本在推理能力上实现了重大突破,同时比 Gemini 2.5 Pro 更具性价比,响应速度更快,欢迎体验:
- Gemini 2.5 Flash 推理版:先思考后回答,适合复杂推理任务
- Gemini 2.5 Flash 标准版:关闭推理模式,响应更快,价格更低
 在确保付费模型高可用的同时,极客智坊对免费 Gemini 模型也同样给予了 1000+ RPM的并发支持,比官方高出 100 倍,你可以按需选择免费/付费模型进行调用,得益于超高并发支持,企业应用场景使用付费版本会更加可靠稳定。
在确保付费模型高可用的同时,极客智坊对免费 Gemini 模型也同样给予了 1000+ RPM的并发支持,比官方高出 100 倍,你可以按需选择免费/付费模型进行调用,得益于超高并发支持,企业应用场景使用付费版本会更加可靠稳定。
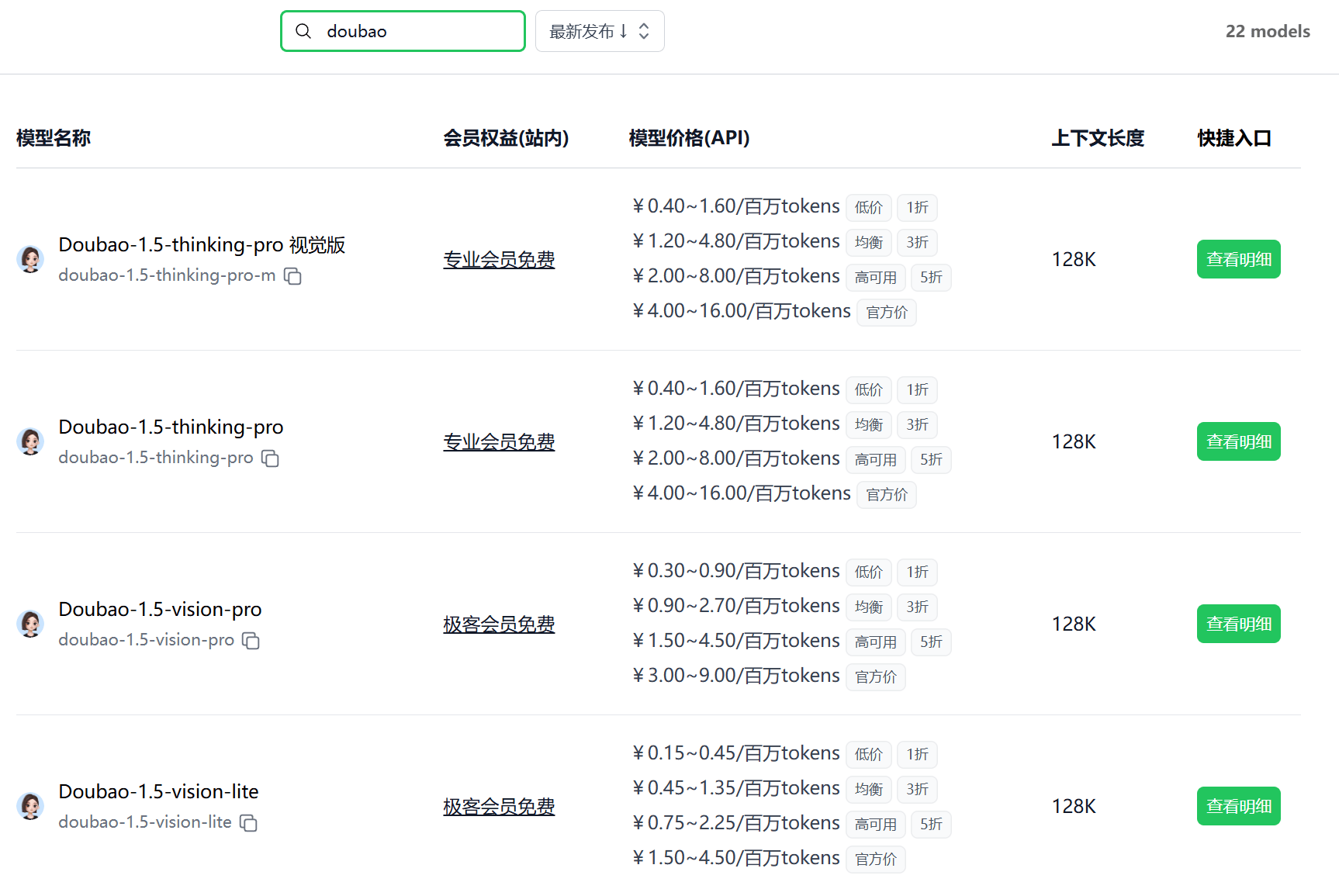
2025.04.18 支持豆包 1.5 视觉及推理模型
 极客智坊已引入对豆包 1.5 系列视觉及推理模型的支持,欢迎体验:
极客智坊已引入对豆包 1.5 系列视觉及推理模型的支持,欢迎体验:
- Doubao-1.5-UI-TARS:豆包原生面向图形界面交互(GUI)的 Agent 模型,通过感知、推理和行动等类人的能力,与 GUI 进行无缝交互。
- Doubao-1.5-vision-lite:豆包全新升级的多模态大模型,相比 Doubao-vision-lite-32k,综合能力大幅提升15%,信息抽取、定位、OCR、图像理解描述等能力提升超20%。
- Doubao-1.5-vision-pro:豆包全新升级的多模态大模型,视觉理解、分类、信息抽取等能力显著提升,并重点增强了解题、视频理解等场景的任务效果。
- Doubao-1.5-thinking-pro:豆包全新深度思考模型,在数学、编程、科学推理等专业领域及创意写作等通用任务中表现突出,仅支持文本输入。
- Doubao-1.5-thinking-pro 视觉版:基于深度思考+视觉理解的混合训练,让模型具备视觉推理能力,更强的多模态交互能力,和更低的视觉描述幻觉。
2025.04.18 支持 Qwen2.5-VL-32B
 极客智坊已引入对 Qwen2.5-VL-32B-Instruct 模型的支持,该模型是一个视觉模型,与之前的 Qwen2.5-VL 系列模型相比,具备以下特性:
极客智坊已引入对 Qwen2.5-VL-32B-Instruct 模型的支持,该模型是一个视觉模型,与之前的 Qwen2.5-VL 系列模型相比,具备以下特性:
- 更符合人类偏好的回答:优化输出风格,生成更详细、格式更佳的答案,使其更贴近人类偏好。
- 数学推理:在解决复杂数学问题方面的准确率得到了显著提升,翻译更加自然易懂。
- 精细图像理解和推理:在图像解析、内容识别以及视觉逻辑推理等任务中实现了准确性的提升和细致的分析。
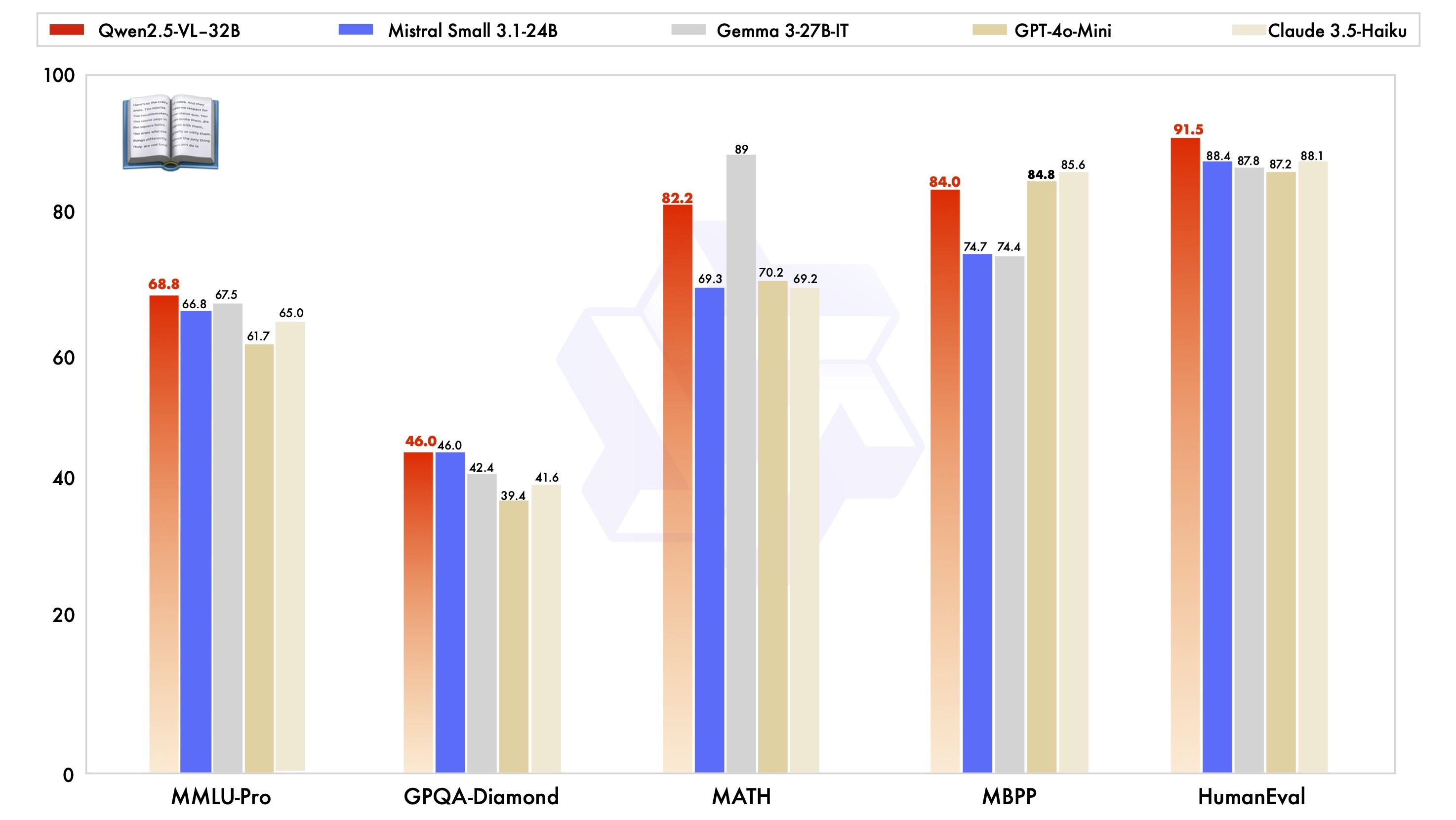
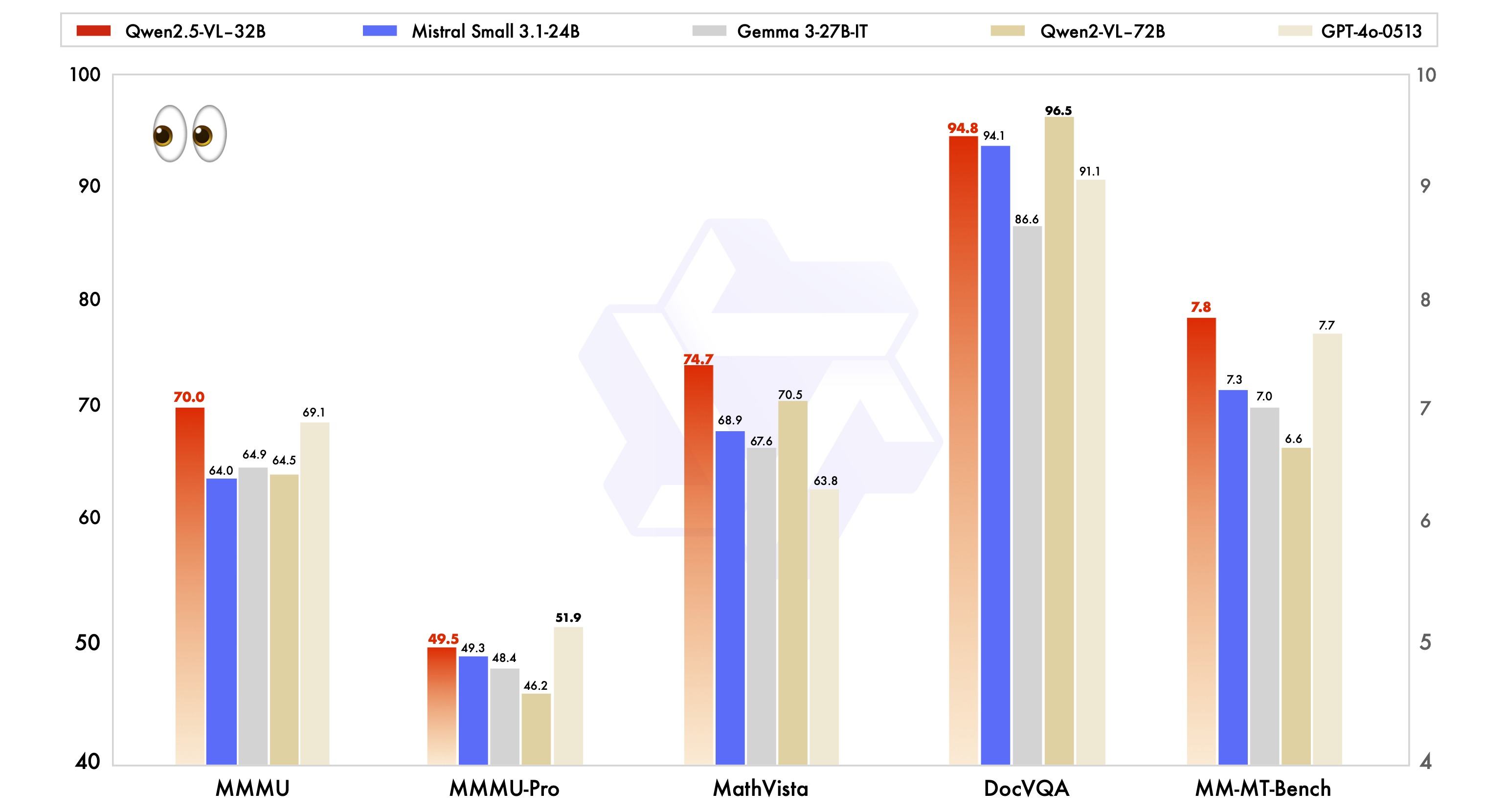 除了在视觉能力上表现出色,Qwen2.5-VL-32B-Instruct 在同一规模下纯文本能力也达到了顶尖水平:
除了在视觉能力上表现出色,Qwen2.5-VL-32B-Instruct 在同一规模下纯文本能力也达到了顶尖水平:
 欢迎体验:
所有模型支持通过极客智坊统一 API 进行调用,你可以在模型广场进行查看和选用。
欢迎体验:
所有模型支持通过极客智坊统一 API 进行调用,你可以在模型广场进行查看和选用。
2025.04.17 支持 o3 和 o4-mini
 极客智坊已引入对 OpenAI 最新发布的 o3 和 o4-mini 模型的支持,这些模型在推理和编码能力上有了显著提升,欢迎体验👉
极客智坊已引入对 OpenAI 最新发布的 o3 和 o4-mini 模型的支持,这些模型在推理和编码能力上有了显著提升,欢迎体验👉
- OpenAI o3:o3 是一个跨领域、全面且强大的模型,在数学、科学、编码和视觉推理任务上树立了新的标杆
- OpenAI o4-mini:OpenAI 最新推出的小型 o 系列模型,专为快速高效的推理而优化,擅长编码、视觉推理任务
- OpenAI o4-mini High:在 OpenAI o4-mini 基础上将推理参数调至最高以获取最好推理效果
 更多关于 API 调用和第三方应用接入的细节,请查阅极客智坊文档教程。
更多关于 API 调用和第三方应用接入的细节,请查阅极客智坊文档教程。
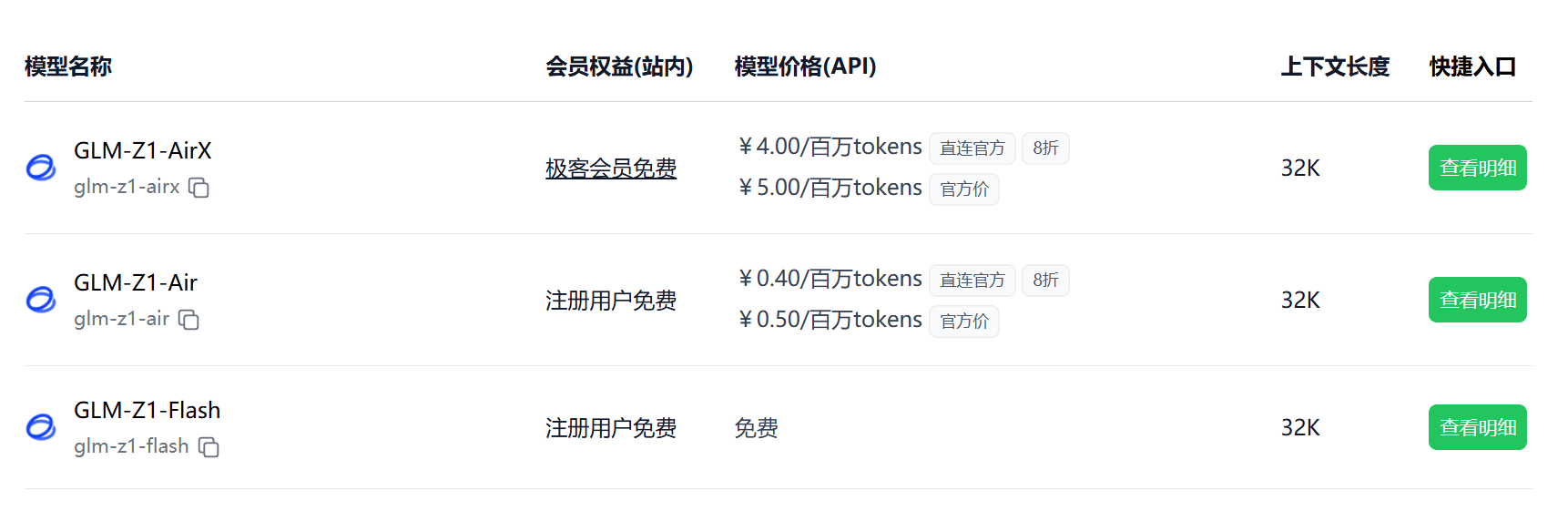
2025.04.15 支持 GLM Z1 系列模型
 极客智坊已引入对 GLM Z1 系列推理模型的支持,该系列模型具备强大的复杂推理能力,在逻辑推理、数学、编程等领域表现优异,欢迎体验:
极客智坊已引入对 GLM Z1 系列推理模型的支持,该系列模型具备强大的复杂推理能力,在逻辑推理、数学、编程等领域表现优异,欢迎体验:
- GLM-Z1-Flash:完全免费的推理模型服务,让每个人都能轻松使用AI
- GLM-Z1-FlashX:GLM-Z1-Flash升级版
- GLM-Z1-Air:专为数理与逻辑推理优化的模型,在对齐阶段深度优化了通用能力,具备更强的泛化能力与速度表现
- GLM-Z1-AirX:国内最快推理模型,推理速度高达200 tokens/s
 且所有付费/免费模型支持比官方更高的并发请求频率,更多关于 API 调用和第三方应用接入的细节,请查阅极客智坊文档教程。
且所有付费/免费模型支持比官方更高的并发请求频率,更多关于 API 调用和第三方应用接入的细节,请查阅极客智坊文档教程。
2025.04.15 支持 GPT 4.1 系列模型
 极客智坊已引入对 OpenAI 最新发布的 GPT 4.1 系列模型的支持,这些模型全面超越 GPT-4o 和 GPT-4o mini,尤其在代码编写和指令遵循方面进步显著:
极客智坊已引入对 OpenAI 最新发布的 GPT 4.1 系列模型的支持,这些模型全面超越 GPT-4o 和 GPT-4o mini,尤其在代码编写和指令遵循方面进步显著:

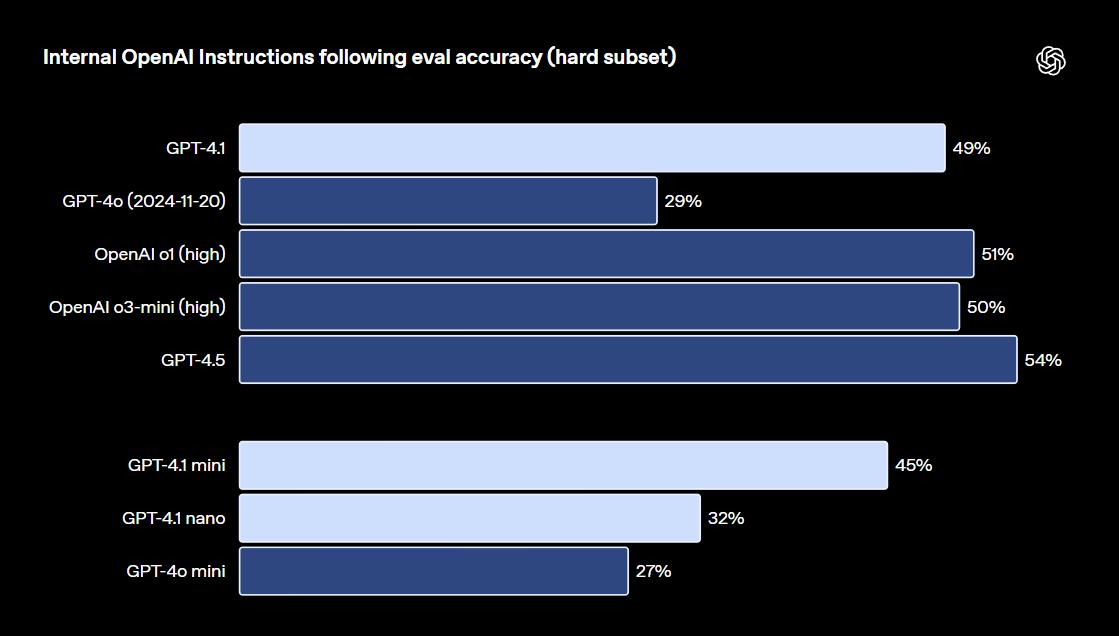 所有 4.1 系列模型支持更大的上下文窗口 —— 最多可达 100 万个tokens,并能更有效地利用这些上下文,增强对长上下文的处理能力。欢迎体验:
所有 4.1 系列模型支持更大的上下文窗口 —— 最多可达 100 万个tokens,并能更有效地利用这些上下文,增强对长上下文的处理能力。欢迎体验:
- GPT 4.1:OpenAI 面向复杂任务旗舰模型,适合解决跨领域问题
- GPT 4.1 mini:在智能、速度和成本之间实现了平衡,这使得它成为日常应用场景下的理想之选
- GPT 4.1 nano:速度最快、性价比最高的 GPT-4.1 模型
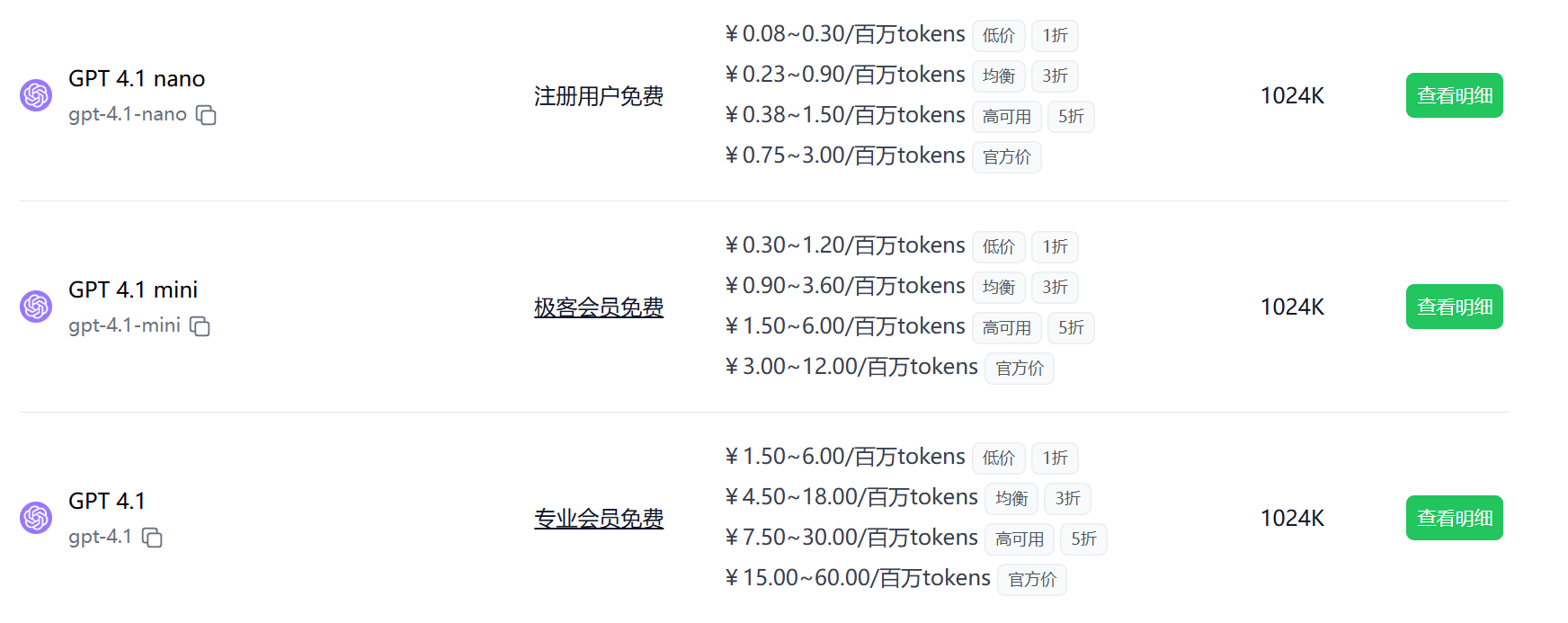 API 调用和第三方应用接入,请查阅极客智坊文档教程。
API 调用和第三方应用接入,请查阅极客智坊文档教程。
2025.04.15 支持 ERNIE X1 模型一览
 极客智坊已引入对百度文心 ERNIE X1 深度推理模型的支持,该模型具备更强的理解、规划、反思、进化能力。作为能力更全面的深度思考模型,文心 X1 兼备准确、创意和文采,在中文知识问答、文学创作、文稿写作、日常对话、逻辑推理、复杂计算及工具调用等方面表现尤为出色。欢迎体验:
极客智坊已引入对百度文心 ERNIE X1 深度推理模型的支持,该模型具备更强的理解、规划、反思、进化能力。作为能力更全面的深度思考模型,文心 X1 兼备准确、创意和文采,在中文知识问答、文学创作、文稿写作、日常对话、逻辑推理、复杂计算及工具调用等方面表现尤为出色。欢迎体验:
2025.04.14 支持 DeepCoder 14B Preview
 极客智坊已引入对 DeepCoder 14B Preview 代码模型的支持,该模型是一个基于 DeepSeek-R1-Distill-Qwen-14B 微调的 14B 参数代码生成模型,通过结合 GRPO+ 强化学习和迭代上下文长度增强进行优化。
该模型有着 96K 的上下文长度,特别适用于长上下文编程,在 LiveCodeBench v5 等编码基准测试中与 o3-Mini 等同类模型相比不分伯仲:
且完全免费,支持 API 调用,欢迎体验!
极客智坊已引入对 DeepCoder 14B Preview 代码模型的支持,该模型是一个基于 DeepSeek-R1-Distill-Qwen-14B 微调的 14B 参数代码生成模型,通过结合 GRPO+ 强化学习和迭代上下文长度增强进行优化。
该模型有着 96K 的上下文长度,特别适用于长上下文编程,在 LiveCodeBench v5 等编码基准测试中与 o3-Mini 等同类模型相比不分伯仲:
且完全免费,支持 API 调用,欢迎体验!
2025.04.14 支持 Nvidia Llama Nemotron 系列
 极客智坊已引入对 NVIDIA Llama Nemotron 系列模型的支持,这些模型针对数据中心到个人电脑等多种平台进行了优化,特别擅长进行研究生级别的科学推理、数学运算、编程、RAG 和工具调用,欢迎体验:
极客智坊已引入对 NVIDIA Llama Nemotron 系列模型的支持,这些模型针对数据中心到个人电脑等多种平台进行了优化,特别擅长进行研究生级别的科学推理、数学运算、编程、RAG 和工具调用,欢迎体验:
- Llama 3.1 Nemotron Nano 8B v1:该模型是由 Meta 的 Llama-3.1-8B-Instruct 衍生而来的紧凑型大语言模型,它在准确性和效率之间取得了平衡,能够轻松地部署在单个消费级 RTX GPU 上。
- Llama 3.3 Nemotron Super 49B v1:该模型基于 Meta 的 Llama-3.3-70B-Instruct 模型,采用神经架构搜索(NAS)技术,大幅提升了效率并减少了内存占用,这使得模型能够在单个高性能 GPU(如 NVIDIA H200)上高效运行。
- Llama 3.1 Nemotron Ultra 253B v1:该模型基于 Meta 的 Llama 3.1-405B-Instruct 模型,通过神经架构搜索(NAS)技术进行了深度定制,实现了效率提升、内存使用降低和推理延迟改善,能够在 8 个 NVIDIA H100 节点上高效运行。
2025.04.11 模型广场支持筛选提示缓存
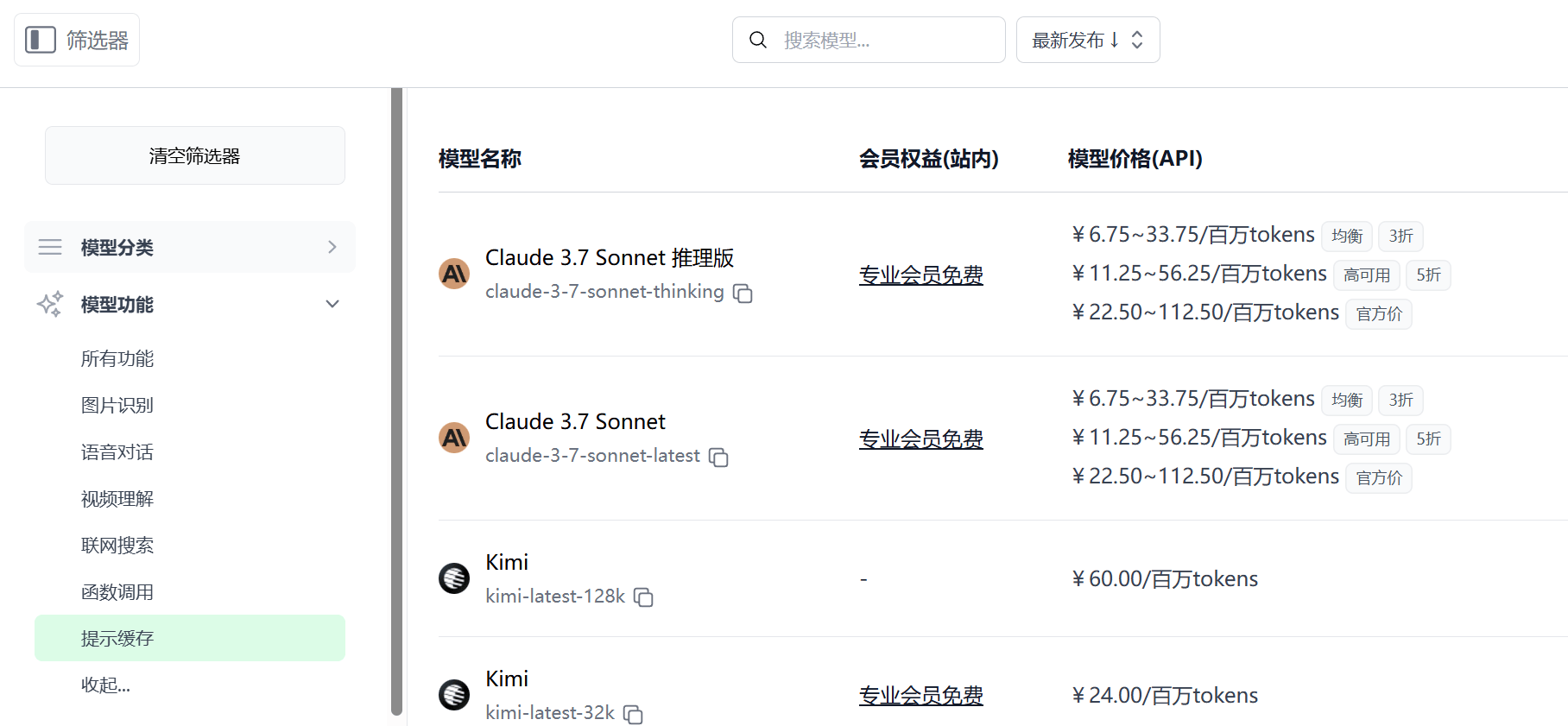 提示缓存技术可以大幅降低官方渠道模型调用成本,极客智坊已支持 OpenAI/Claude/DeepSeek 等主流 AI 模型的提示缓存,你可以在模型广场通过提示缓存筛选查看所有支持提示缓存的模型。关于提示缓存的开启和价格信息,请参考提示缓存文档。
提示缓存技术可以大幅降低官方渠道模型调用成本,极客智坊已支持 OpenAI/Claude/DeepSeek 等主流 AI 模型的提示缓存,你可以在模型广场通过提示缓存筛选查看所有支持提示缓存的模型。关于提示缓存的开启和价格信息,请参考提示缓存文档。
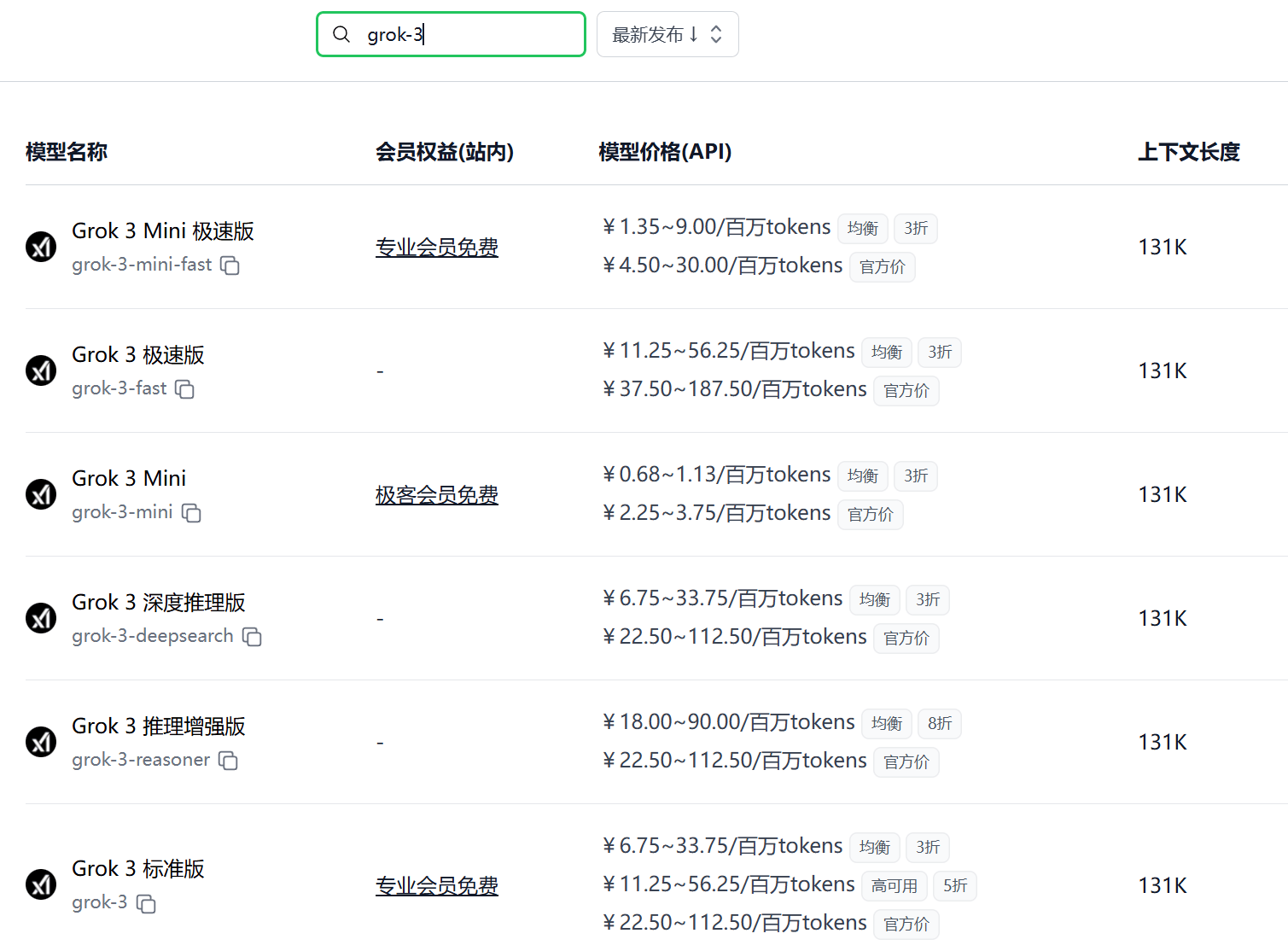
2025.04.10 支持 Grok 3 系列模型及 API
 极客智坊已支持 xAI 最新发布的 Grok 3 系列推理模型,欢迎体验👉
极客智坊已支持 xAI 最新发布的 Grok 3 系列推理模型,欢迎体验👉
- Grok 3 标准版:xAI 最新一代推理对话模型旗舰版,具备丰富金融、医疗、法律和科学等领域知识,适用于数据提取、编程任务、文本总结等企业业务。
- Grok 3 Mini:xAI 最新一代推理对话模型轻量版,速度快、智能度高,适用于不需要领域知识的逻辑推理任务。
- Grok 3 极速版:Grok 3 极速版,模型和性能与标准版一致,响应速度更快。
- Grok 3 Mini 极速版:Grok 3 Mini 极速版,模型和性能与标准版一致,响应速度更快。
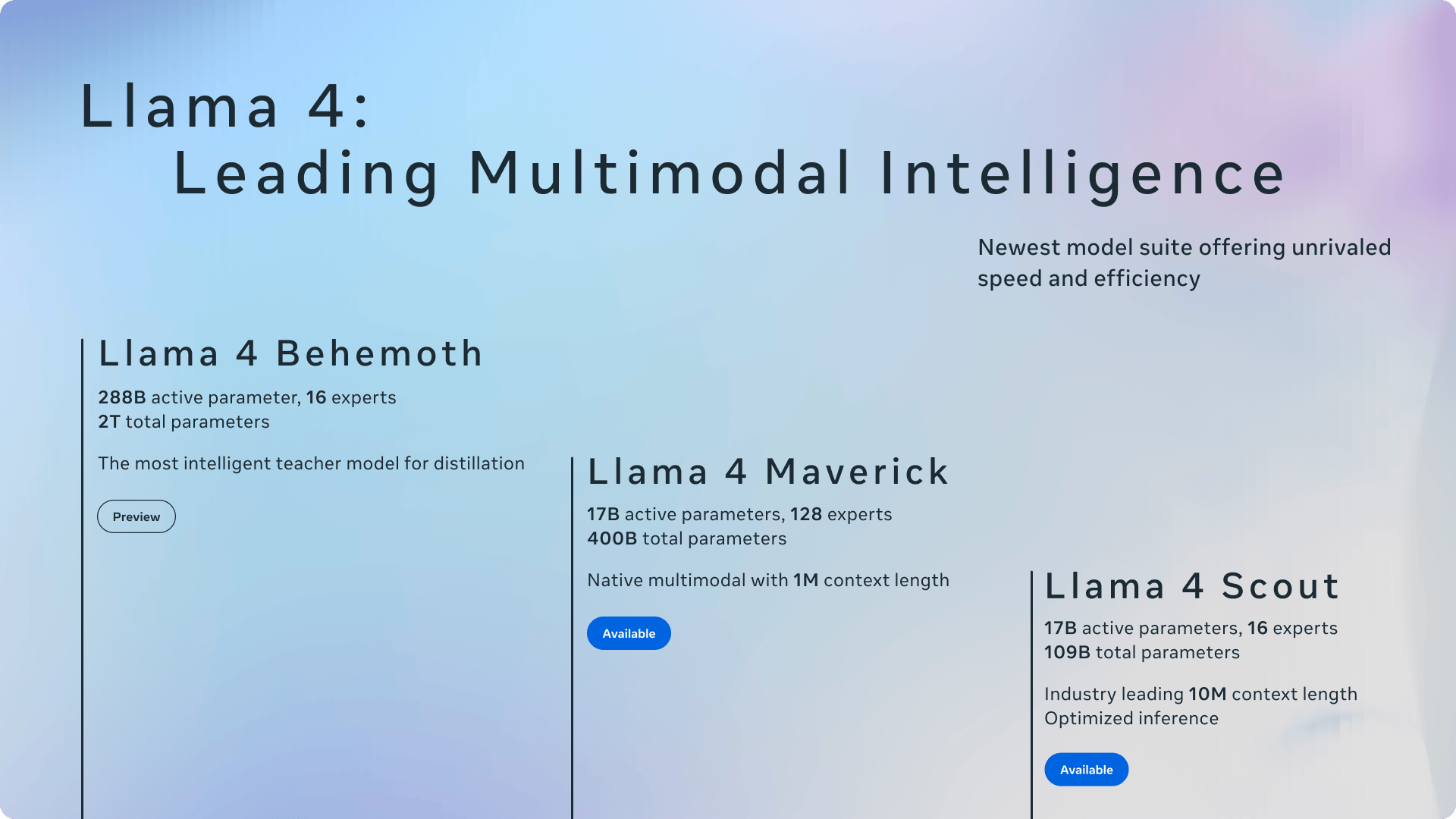
2025.04.06 支持 Llama 4 Scout & Maverick 模型
 极客智坊已支持 Meta 最新发布的 Llama 4 系列开源模型 Scout 和 Maverick,欢迎体验:
极客智坊已支持 Meta 最新发布的 Llama 4 系列开源模型 Scout 和 Maverick,欢迎体验:
- Llama 4 Scout:一个由 16 位专家组成的 170 亿参数模型,在同类多模态模型中表现卓越,其性能超越了所有上一代 Llama 模型,并且只需单个 NVIDIA H100 GPU 即可运行。更重要的是,它拥有业界领先的 10M 上下文窗口,在多个广泛报道的基准测试中均超越了 Gemma 3、Gemini 2.0 Flash-Lite 和 Mistral 3.1。
- Llama 4 Maverick:一个由 128 位专家组成、拥有 17 亿个活跃参数的模型,被誉为同类最佳的多模态模型。在众多基准测试中,它超越了 GPT-4o 和 Gemini 2.0 Flash,同时在推理和编码能力上与 DeepSeek v3 不相上下,而其参数数量仅为后者的四分之一。这款模型在性能与成本比上具有显著优势,其聊天版本在 LMArena 上的 ELO 评分高达 1417。
2025.04.04 支持筛选 API 免费模型
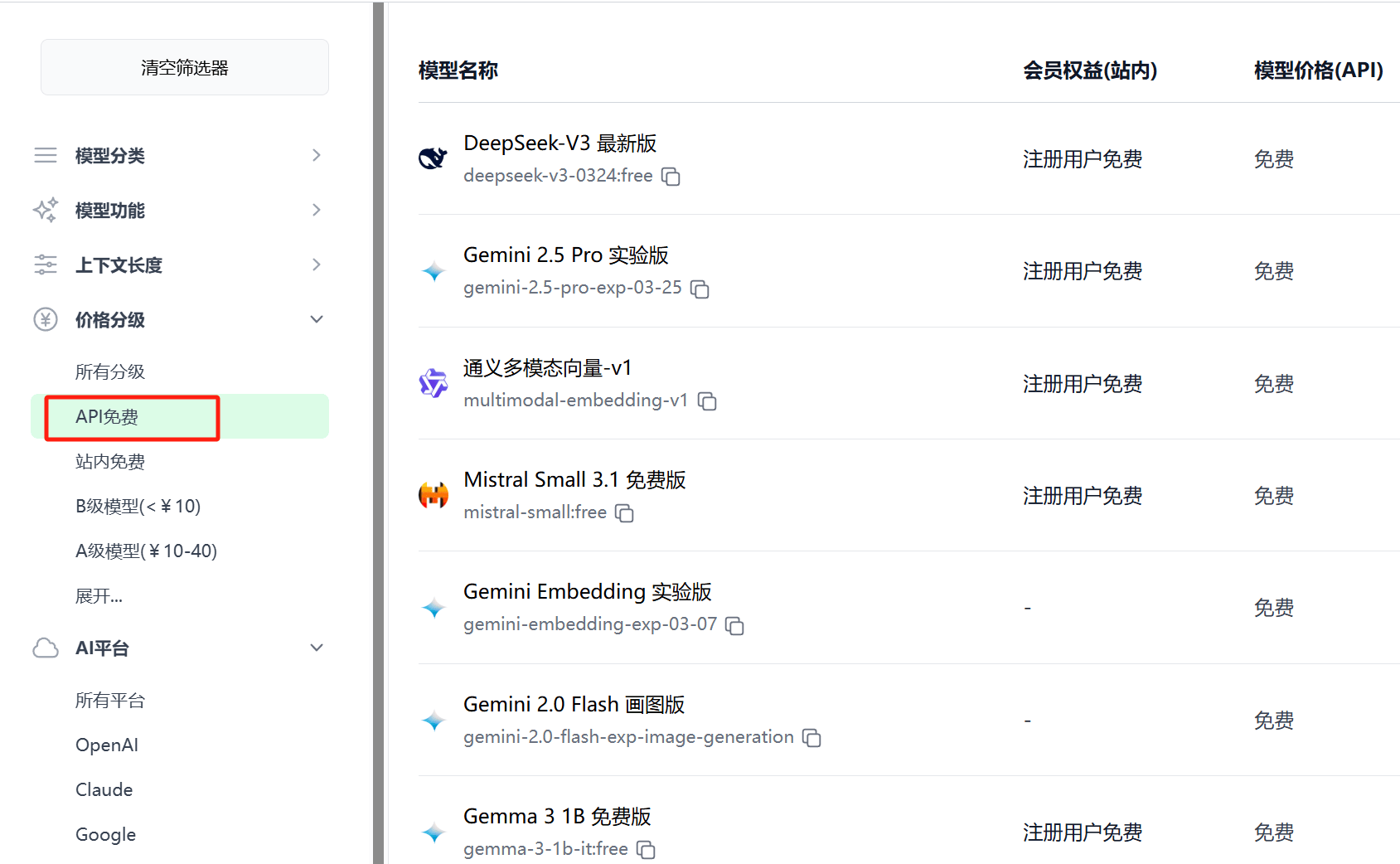 极客智坊已支持在模型广场筛选 API 免费调用的 AI 模型,目前已覆盖 DeepSeek、Gemini、智谱清言等多个平台,涉及对话、推理、画图、向量化等多个功能维度的 31 个免费模型,且这一数量还在继续增加,欢迎来极客智坊薅免费调用的 AI 模型:
极客智坊已支持在模型广场筛选 API 免费调用的 AI 模型,目前已覆盖 DeepSeek、Gemini、智谱清言等多个平台,涉及对话、推理、画图、向量化等多个功能维度的 31 个免费模型,且这一数量还在继续增加,欢迎来极客智坊薅免费调用的 AI 模型:
2025.04.03 支持 Stable Image 和 Video 模型
 极客智坊已引入对 Stability AI 旗下画图模型和视频生成模型的支持,欢迎体验:
极客智坊已引入对 Stability AI 旗下画图模型和视频生成模型的支持,欢迎体验:
- Stable Image Ultra:基于 Stable Diffusion 3.5 Large 的旗舰级画图模型,画质和细节达到行业最高标准
- Stable Image Core:基于 Stable Diffusion 的轻量级画图模型,低成本、低延迟
- Stable Video:业界领先的 Stable Video Diffusion 模型,能够基于图片生成短视频
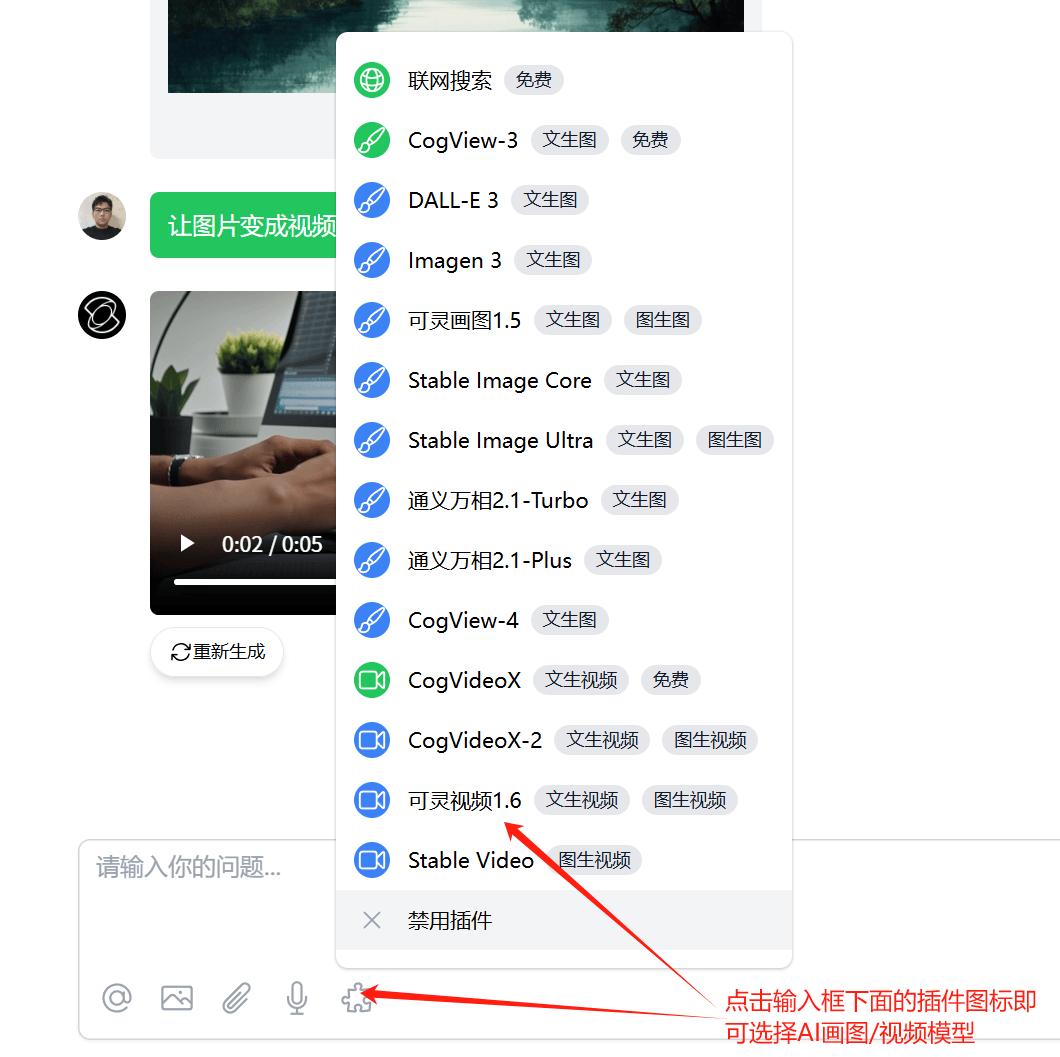 所有画图/视频模型均支持通过 API 调用,调用细节请参考API 手册。
所有画图/视频模型均支持通过 API 调用,调用细节请参考API 手册。
2025.04.02 支持可灵 AI 画图&视频模型
 极客智坊已引入对可灵 AI 旗下独立画图模型和视频生成模型的支持,所有模型支持文本、图片输入,欢迎体验:
和 GPT-4o/Gemini-2.0-Flash 画图版不同的是,这些独立画图/视频模型仅支持通过文本提示/图片引用进行画图/视频生成,不支持上下文对话。
以上所有模型均支持通过 API 调用,调用细节请参考API 手册。
极客智坊已引入对可灵 AI 旗下独立画图模型和视频生成模型的支持,所有模型支持文本、图片输入,欢迎体验:
和 GPT-4o/Gemini-2.0-Flash 画图版不同的是,这些独立画图/视频模型仅支持通过文本提示/图片引用进行画图/视频生成,不支持上下文对话。
以上所有模型均支持通过 API 调用,调用细节请参考API 手册。
2025.04.01 支持 Cohere Embed 3 向量模型
 极客智坊已引入对 Cohere 旗下最新版本向量模型 Embed 3 系列的支持:
极客智坊已引入对 Cohere 旗下最新版本向量模型 Embed 3 系列的支持:
- Embed v3 英文版,支持 1024 维度
- Embed v3 多语言版,支持 1024 维度
- Embed v3 英文轻量版,支持 384 维度
- Embed v3 多语言轻量版,支持 384 维度