HappyHorse-1.0
happyhorse-t2v 创建一个快乐马文生视频技能happyhorse-t2v,对应生成示例如下:data:{MIME_type};base64,{base64_data},多张图片以数组形式传入。
当task_status=succeed时,通过 video_result 数组中第一个元素的 url 字段提取视频结果 URL,并作为最终输出结果,否则提示视频生成失败并提取错误信息输出,设置系统环境变量GEEKAI_API_KEY值为sk-xxxxxxxxxx,并设置超时时间为10分钟
happyhorse-1.0-i2v
创建一个快乐马首帧生视频技能happyhorse-1.0-i2v,对应生成示例如下:
data:{MIME_type};base64,{base64_data}。
当task_status=succeed时,通过 video_result 数组中第一个元素的 url 字段提取视频结果 URL,并作为最终输出结果,否则提示视频生成失败并提取错误信息输出,设置系统环境变量GEEKAI_API_KEY值为sk-xxxxxxxxxx,并设置超时时间为10分钟
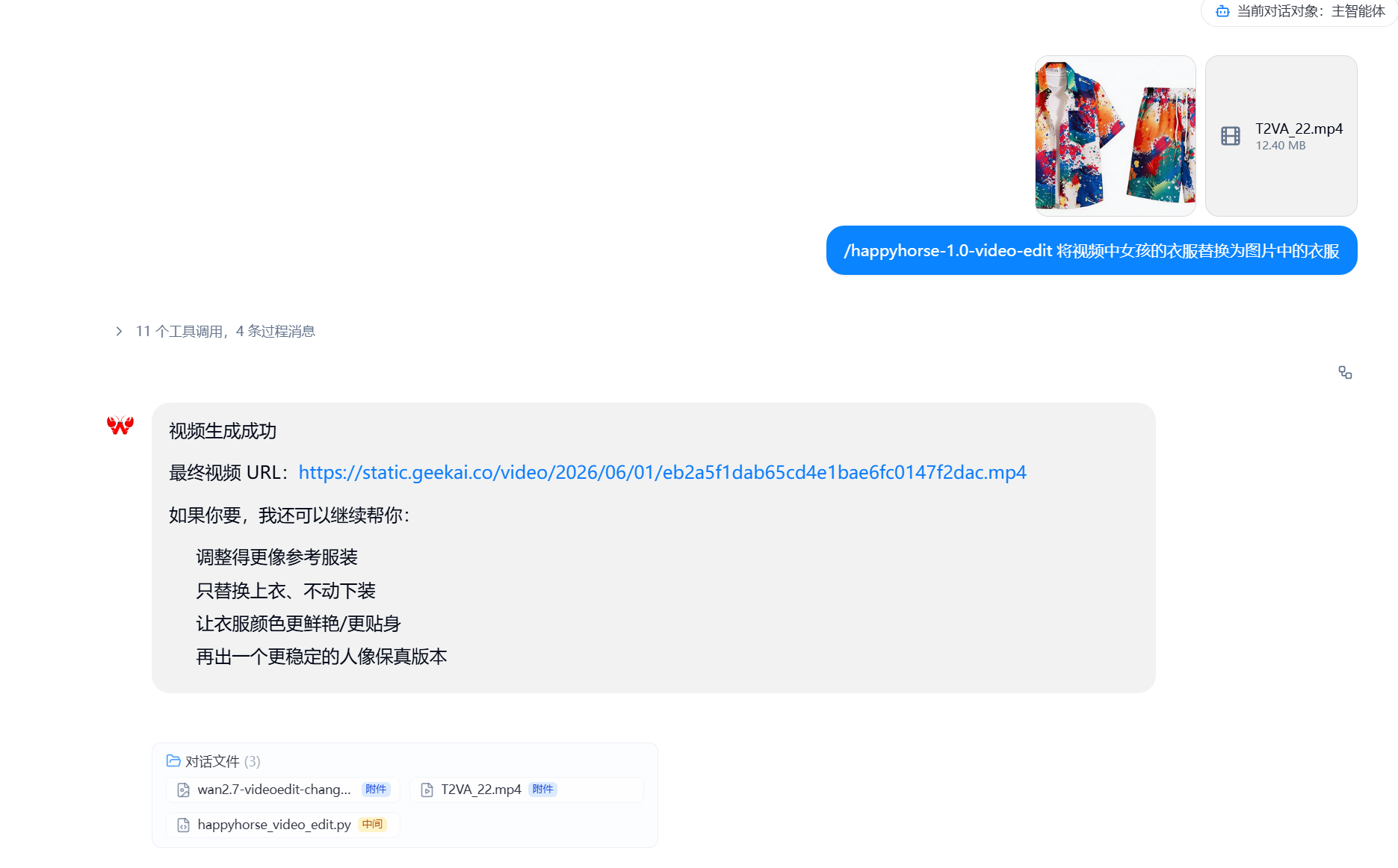
happyhorse-1.0-video-edit
创建一个快乐马视频编辑技能happyhorse-1.0-video-edit,对应生成示例如下:
data:{MIME_type};base64,{base64_data},多张图片以数组形式传入。
当传入的是视频请把本地视频上传成公网可访问 URL传递到video参数。
当task_status=succeed时,通过 video_result 数组中第一个元素的 url 字段提取视频结果 URL,并作为最终输出结果。否则提示视频生成失败并提取错误信息输出,设置系统环境变量GEEKAI_API_KEY值为sk-xxxxxxxxxx,并设置超时时间为10分钟
kling-video-v3-omni
创建一个可灵视频生成技能kling-video-v3-omni,支持三种生成模式,对应生成示例如下:- 当用户只提供文本 prompt,且未提供图片时,使用模式一(纯文本生成视频)。
- 当用户提供图片,且没有镜头描述时,使用模式二(图片生成视频)。
- 当用户提供图片,且包含多个镜头描述时,使用模式三(多镜头生成)。
- 传入的图片需要添加到 extra_body.image_list 数组中。
- image_list 中每个元素包含:
- type:首帧即一张图片设置为first_frame,尾帧即第二张图片设置为end_frame
- image_url:如果是公网 URL,则直接传递到 image_url 参数里面,如果不是 URL,则先上传为公网可访问 URL 再传递到 image_url 参数里面。
- 当传入多张图片时,需要按顺序依次添加到 image_list 数组中。
- 将每个镜头分别映射为 extra_body.multi_prompt 数组中的一个元素。
- multi_prompt 中每个元素对应一个独立镜头,并包含以下字段:
- index:镜头顺序,从 1 开始递增
- prompt:该镜头的具体描述
- duration:该镜头时长,单位为秒
- 多个镜头按用户描述顺序依次加入 multi_prompt 数组。
- 如果某个镜头引用了参考图,则可在该镜头 prompt 中使用
<<<image_1>>>、<<<image_2>>>等占位符,并与 image_list 中的图片顺序对应。 - 最终总时长应与各镜头 duration 之和保持一致;如果用户未单独指定总时长,则自动根据各镜头 duration 求和填写 duration 字段。
- 用户传入图片时,如果是公网 URL,则直接传递到 image 参数。如果不是 URL,则可以使用litterbox.catbox.moe 这个匿名文件上传服务将图片上传为公网可访问 URL 再传递到image参数,
- 多镜头模式下,如需引用图片,也应先确保图片已转换为公网可访问 URL,再写入 extra_body.image_list。
- 当 task_status = succeed 时,通过 video_result 数组中第一个元素的 url 字段提取视频结果 URL,并作为最终输出结果。否则则提示视频生成失败并提取错误信息输出。
- 设置系统环境变量 GEEKAI_API_KEY 值为sk-xxxxxxxxxx
- 超时时间设置为 10 分钟。

kling-video-v3
创建一个可灵视频生成技能kling-video-v3,支持三种生成模式,对应生成示例如下:- 当用户只提供文本prompt时,使用模式一(纯文本生成)
- 当用户提供图片时:
- 如果只有一个prompt,使用模式二(图片生成视频)
- 如果有多个镜头描述,使用模式三(多镜头生成),多个镜头,处理规则如下:
- 将每个镜头分别映射为 extra_body.multi_prompt 数组中的一个元素
- multi_prompt 中每个元素对应一个独立镜头
- index 按镜头顺序从 1 开始递增
- prompt 填写该镜头的具体描述
- duration 填写该镜头时长,单位为秒
- 多个镜头按用户描述顺序依次加入 multi_prompt 数组
- 最终总时长应与各镜头 duration 之和保持一致,或自动按各镜头时长求和填写 duration 字段
- 图片参数:
- 用户传入图片时,如果不是URL链接,则使用litterbox.catbox.moe 这个匿名文件上传服务将图片上传为公网可访问 URL 再传递到image参数,如果是URL链接,则直接传递到image参数
- 当task_status=succeed时,通过 video_result 数组中第一个元素的 url 字段提取视频结果 URL,并作为最终输出结果。
- 否则提示视频生成失败并提取错误信息输出
- 设置系统环境变量GEEKAI_API_KEY值为sk-xxxxxxxxxx
- 设置超时时间为10分钟
注意:kling-video-v3-omni和kling-video-v3的中,图片需要一个完整的公网可访问的url,litterbox.catbox.moe 这个匿名文件上传服务如果不可以的话,可以使用极客智坊的上传文件接口来获取url,这样在对话中可直接使用url
Doubao-Seedance-2.0
创建一个豆包视频生成技能doubao-seedance-2.0,支持三种生成模式,对应生成示例如下:- 当用户只提供文本prompt时,使用模式一(纯文本生成)
- 当用户提供图片时:
- 当用户明确使用首帧、首尾帧图生视频,或提供首帧图与尾帧图,并应通过 image 和可选的 image_tail 参数传入时,使用模式二(图片生成视频)。
- 当用户明确使用参考素材生成,或参考图片需要通过 images 数组传入,或同时提供参考视频、参考音频中的一种或多种素材时,使用模式三(参考视频生成)。 图片参数处理规则:
- 模式二中:
- image 参数用于传入首帧参考图
- image_tail 参数用于传入尾帧参考图(可选)
- 模式三中:
- images 参数为数组,支持传入一张或多张参考图片
- 即使只有一张参考图片,只要该图片需要通过 images 数组传入,也应使用模式三
- 如果用户传入的是公网 URL,则直接传递到对应参数。
- 如果用户传入的不是 URL,而是本地文件,则需要litterbox.catbox.moe 这个匿名文件上传服务上传为公网可访问 URL,再传递到对应参数。
- 模式三中,video 、audio 参数用于传入参考视频、参考音频、是需要公网可访问的 URL
- 模式三中,images 数组中的图片顺序需要与 prompt 中 @图1、@图2、@图3 的引用顺序保持一致。 异步任务处理规则
- 调用创建接口后:
- 如果返回 task_status = pending,说明任务已提交成功,需要从返回结果中提取 task_id
- 提取 task_id 后,继续调用查询接口轮询任务状态 查询结果处理规则:
- 当 task_status = pending 或 running 时,表示任务仍在处理中,需要继续轮询查询接口
- 当 task_status = succeed 时,通过 video_result 数组中第一个元素的 url 字段提取视频结果 URL,并作为最终输出结果。
- 当 task_status = failed 时,提示视频生成失败,并提取错误信息输出
- 轮询超时时间设置为 10 分钟
- 如果超过 10 分钟任务仍未完成,则返回“任务仍在处理中”,并输出 task_id 供后续继续查询 其他要求
- 设置系统环境变量 GEEKAI_API_KEY 的值为 sk-xxxxxxxxxx
- 创建和查询使用的GEEKAI_API_KEY 是一样的,可以共用
- 超时时间设置为 10 分钟
注意:dobao-seedance-2.0-fast和doubao-seedance-2.0的接口和参数基本一致,只需替换对应的名称model即可,
另外,doubao-seedance-2.0的图片images,iamge_tail ,image,video,audio参数,需要一个完整的公网可访问的url,如果上述不可以的话,可以使用极客智坊的上传文件接口来获取url,这样在对话中可直接使用
Veo 3.1-Lite-Generate-Preview
生成一个veo-3.1-lite-generate-preview视频生成技能,对应生成示例如下:{base64_data},直接使用base64,不需要data:{MIME_type};base64,前缀:
- 传入单张图片,使用image参数传入
- 传入两张图片,第一张通过image参数传入,第二张通过image_tail参数传入
Nano Banana 2
生成一个nano-banana-2生图技能,对应生成示例如下:data:image/png;base64,${base64_data}的格式进行传递。
当task_status=succeed时,则返回响应并提取 data 数组中第一个元素的 url 字段值作为图片地址输出,否则返回错误信息。
生图耗时长,将超时时间设置为5分钟。设置系统环境的GEEKAI_API_KEY的值为sk-xxxxxxxxxx
GPT-Image-2
生成一个gpt-image-2生图技能,对应生成示例如下:- 单张图片从image参数传递,对应image_url字段值支持base64和http链接两种格式。
- 多张图片从images参数传递,对应image_url字段值支持base64和http链接两种格式,多个图片以数组形式传递到image数组里面。
如果传入的图片要使用base64编码,则需要将图片数据进行base64编码,并使用
data:{MIME_type};base64,{base64_data}的格式进行传递。 当task_status=succeed时,则返回响应并提取 data 数组中第一个元素的 url 字段值作为图片地址输出,否则返回错误信息。 生图耗时长,将超时时间设置为5分钟。设置系统环境的GEEKAI_API_KEY的值为sk-xxxxxxxxxx。
gpt-image-1.5和gpt-image-2模型使用的方法一样,替换对应的模型名称即可
Doubao-Seedream-5.0-Lite
生成一个doubao-seedance-5.0-lite生图技能,对应生成示例如下:data:{MIME_type};base64,{base64_data}的格式进行传递
当task_status=succeed时,则返回响应并提取 data 数组中第一个元素的 url 字段值作为图片地址输出,否则返回错误信息。
生图耗时长,将超时时间设置为5分钟。设置系统环境的GEEKAI_API_KEY的值为sk-xxxxxxxxxx。
Doubao-Transcribe
生成一个doubao-transcribe语音转录技能,对应生成示例如下:- 以 http:// 或 https:// 开头的公网可访问音频 URL
- base64 编码的音频数据
audio.format 用于指定音频格式,可选值包括 mp3、wav 等,应根据实际文件格式填写。
如果用户传入的是公网音频 URL,则直接传递到 audio.url。
如果用户传入的是本地音频文件或其他非 URL 音频内容,则先转换为 base64 编码,格式为
{base64_data},直接使用base64不需要data:{MIME_type};base64,前缀,再传递到 audio.url。 如果用户未明确提供音频格式,则优先根据文件扩展名判断;若无法判断,则根据 MIME 类型或内容推断。
- 调用成功返回结果后,从响应中提取以下字段:
- text:转录后的文本内容
- id:转录结果 ID
- duration:音频时长,单位为秒 默认优先输出 text 如需补充信息,可同时输出 id 和 duration 如果接口调用失败,则提示“语音转录失败”,并输出错误信息
GPT-4o-Transcribe
生成一个gpt-4o-transcribe语音转录技能,对应生成示例如下:- file 参数用于传入待转录的音频文件。
- model 固定设置为 gpt-4o-transcribe。
- response_format 固定设置为 json。 如果用户传入的是本地音频文件,则直接作为 file 参数上传。 如果用户传入的是公网可访问的音频 URL,则先下载音频文件,再以 file 参数的形式上传。 如果用户传入的是 base64 编码的音频数据,则先解码为音频文件,再以 file 参数的形式上传。 音频格式可为 mp3、wav 等常见格式,实际上传时根据原始文件格式保留对应扩展名。
- id:转录结果 ID
- text:转录结果内容
- duration:音频时长,单位为秒 需要注意:返回结果中的 text 字段可能是一个 JSON 字符串,而不是直接的纯文本。 如果 text 字段是 JSON 字符串,则需要先将其解析为 JSON 对象,再提取其中的 text 字段作为最终转录文本。 默认优先输出解析后的最终转录文本。 如有需要,可同时附带输出 id 和 duration 信息。 如果接口调用失败,则提示“语音转录失败”,并输出错误信息。